
hyeonga_code
Database_66_Subquery 응용_다중 열 서브쿼리, 쌍 비교, 비쌍 비교, 스칼라 서브쿼리, Correlated 상호관련 서브쿼리, EXISTS 연산 본문
Database_66_Subquery 응용_다중 열 서브쿼리, 쌍 비교, 비쌍 비교, 스칼라 서브쿼리, Correlated 상호관련 서브쿼리, EXISTS 연산
hyeonga 2023. 8. 20. 09:59
-- Advanced Subquery
-- 다중 열 서브쿼리
-- 두 개 이상의 열을 비교하기 위해 논리 연산자를 사용하여 혼합 WHERE 절을 작성합니다.
-- 메인쿼리의 각 행은 Multiple_row/Multiple_column 서브쿼리의 값과 비교됩니다.
/*
SELECT column, column..
FROM table
WHERE ( column, column..) IN ( SELECT column, column..
FROM table
WHERE condition );
*/
-- 비교 방식
-- Pairwise_쌍 비교
-- Nonpairwise_비쌍 비교
-- 데이터의 전체 개수를 확인합니다.
SELECT COUNT(*) FROM empl_demo;

-- 이름이 John인 직원을 조회합니다.
SELECT first_name, manager_id, department_id
FROM empl_demo
WHERE first_name='John';
-- 이름이 같은 직원이 여럿 있는 경우 여러 개의 컬럼 값이 일치하는 사람을 찾아야 합니다.

-- 조건 1식
SELECT manager_id, department_id
FROM empl_demo
WHERE first_name='John';

-- 쌍 비교
-- 나열된 값을 순선대로 작성합니다.
-- 서브쿼리가 독립적으로 사용되므로 메인쿼리 실행 시 John이 두번 조회될 수 있습니다.
-- 중복을 막기 위해 AND 절을 작성합니다.
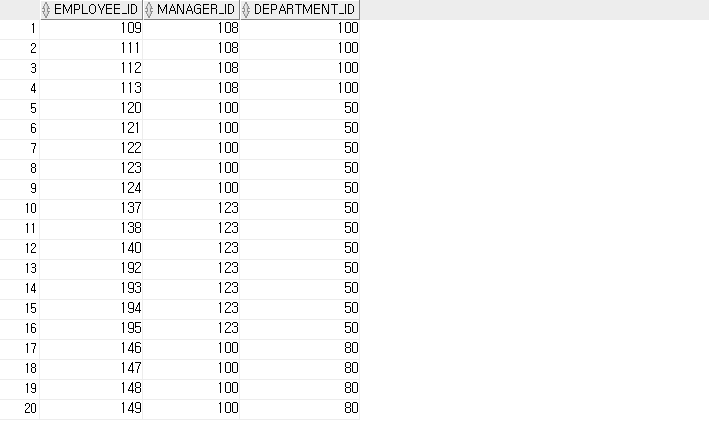
SELECT employee_id, manager_id, department_id
FROM empl_demo
WHERE (manager_id, department_id) IN ( SELECT manager_id, department_id
FROM empl_demo
WHERE first_name='John')
AND first_name <> 'John';

-- 조건 1식
SELECT manager_id
FROM empl_demo
WHERE first_name = 'John';

-- 조건 2식
SELECT department_id
FROM empl_demo
WHERE first_name = 'John';

-- 비쌍 비교
SELECT employee_id, manager_id, department_id
FROM empl_demo
WHERE manager_id IN ( SELECT manager_id
FROM empl_demo
WHERE first_name = 'John' )
AND department_id IN ( SELECT department_id
FROM empl_demo
WHERE first_name = 'John' )
AND first_name <> 'John';
-- 스칼라 서브쿼리식
-- SELECT 문에서 열 또는 표현식 처럼 사용되는 하나의 행에서 하나의 열 값만 반환하는 서브쿼리입니다.
-- 결과는 반드시 하나의 열에 하나의 값이어야 합니다.
-- 서브 쿼리의 SELECT 목록에 있는 항목의 값입니다.
-- NULL 값을 가질 수 있습니다.
-- 두 개 이상의 값을 반환하는 경우 오류가 발생합니다.
-- 사용하는 경우
-- SELECT 절의 DECODE 및 CASE의 조건 및 표현식 부분
-- GROUP BY를 제외한 SELECT의 모든 절
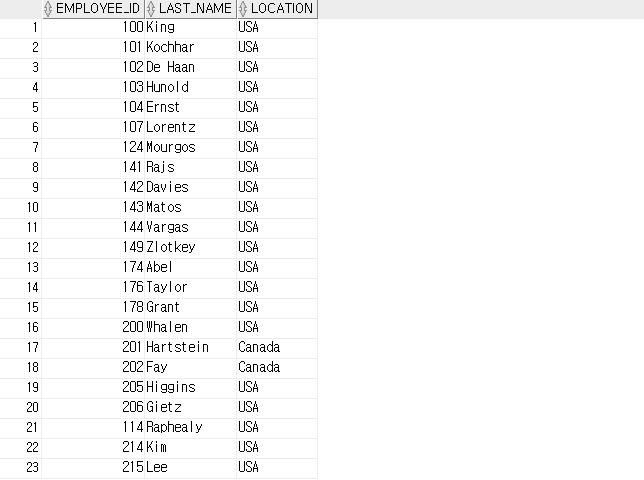
SELECT employee_id, last_name,
CASE WHEN department_id=( SELECT department_id
FROM departments
WHERE location_id=1800 )
THEN 'Canada' ELSE 'USA' END AS location
FROM employees;
-- JOIN을 사용하지 않고 JOIN 결과를 반환할 수 있습니다.
-- 서브 쿼리에 결과 데이터가 없는 경우 NULL을 반환합니다.
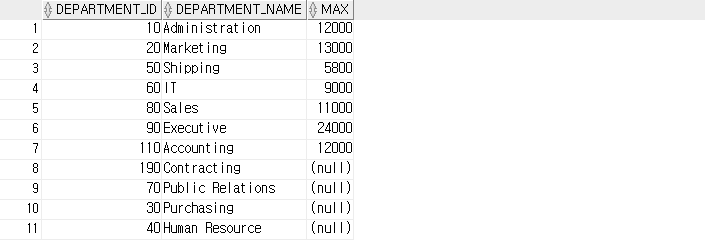
SELECT d.department_id, d.department_name,
( SELECT MAX(salary)
FROM employees
WHERE department_id=d.department_id) AS MAX
FROM departments d;
-- Correlated_상호관련 서브쿼리
/*
SELECT column1, column2...
FROM table1 outer_table
WHERE column1 operator ( SELECT column1, column2
FROM table2
WHERE expr1 = outer_table.expr2);
GET >> EXECUTE >> USET>> GET.... 반복
-- GET : 외부 질의의 후보 행을 호출합니다.
-- EXECUTE : 후보 행 값을 사용하여 내부 질의를 실행합니다.
-- USE : 내부 질의의 결과 값을 사용하여 후보 행을 검증합니다.
-- 후보 행이 남지 않을 때까지 반복합니다.
*/
-- 서브쿼리가 상위 문에서 참조되는 테이블의 열을 참조합니다.
-- 각 서브쿼리는 상위 문에서 처리되는 각 행에 대해 한 번씩 평가되어 질의의 모든 행에 대해 한 번씩 실행됩니다.
-- 서브쿼리는 상위 쿼리 테이블의 열을 참조합니다.
-- 회사의 모든 부서의 평균 급여와 비교합니다.
SELECT employee_id, last_name, salary
FROM employees
WHERE salary> ANY( SELECT AVG(salary)
FROM employees
GROUP BY department_id);
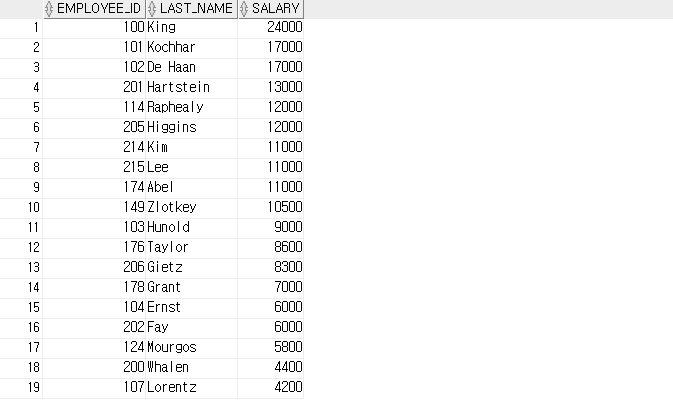
-- 부서별 평균 급여를 조회합니다.
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;

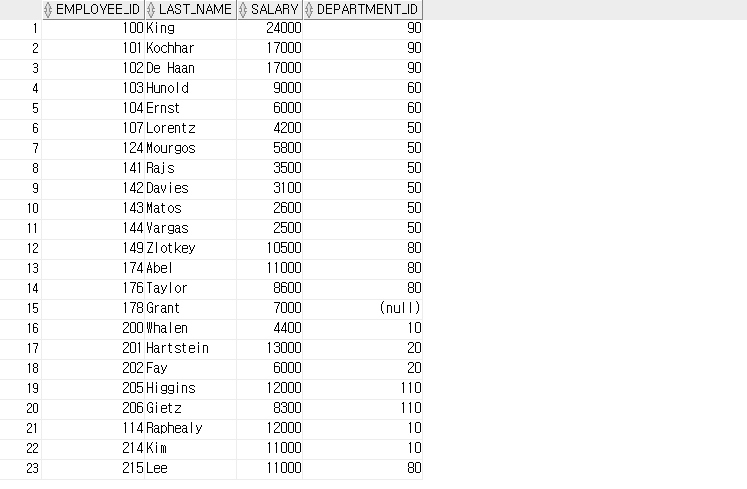
-- 직원들의 부서와 급여를 조회합니다.
SELECT employee_id, last_name, salary, department_id
FROM employees;
-- 서브쿼리의 부서 번호를 변수와 비교하여 값을 출력해야 합니다.
SELECT last_name, salary, department_id
FROM employees outer
WHERE salary>( SELECT AVG(salary)
FROM employees
WHERE department_id= outer.department_id);

-- EXISTS 연산자
-- 서브쿼리의 결과 집합에 행이 있는지 테스트합니다.
-- 데이터가 많지만 중복이 많은 경우에 많이 사용됩니다.
-- 값이 존재하는 지만 확인하는 데에 많이 사용됩니다.
-- 서브쿼리 행에 값이 있는 경우
-- 검색이 INNER QUERY에서 계속 수행되지 않습니다.
-- 조건은 TRUE로 플래그가 지정됩니다.
-- 조건은 TRUE로 플래그가 지정됩니다.
-- 서브쿼리 행에 값이 없는 경우
-- 조건은 FALSE로 플래그가 지정됩니다.
-- 검색이 INNER QUERY에서 계속 수행됩니다.
-- NOT EXISTS 연산자
-- 데이터를 조회합니다.
SELECT employee_id, last_name, manager_id
FROM employees;

-- EXISTS 연산자를 사용하여 부하직원이 있는 사원을 조회합니다.
SELECT employee_id, last_name, job_id, department_id
FROM employees outer
WHERE EXISTS ( SELECT 'X'
FROM employees
WHERE manager_id=outer.employee_id );
-- 'X' : 플래그, 표시자라고 합니다.
-- IN 연산자를 사용한 결과와 동일합니다.
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN ( SELECT manager_id
FROM employees
WHERE manager_id IS NOT NULL );
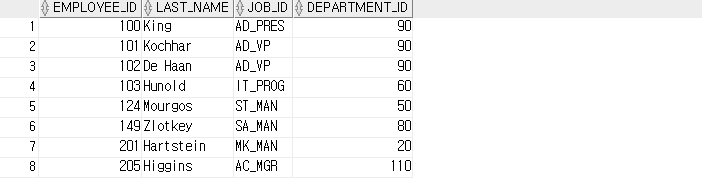
-- 성능 면에서 EXISTS 연산자를 사용하는 것이 좋습니다.
-- NOT EXISTS 연산자를 사용하여 사원이 없는 부서를 조회합니다.
SELECT department_id, department_name
FROM departments d
WHERE NOT EXISTS ( SELECT 'X'
FROM employees
WHERE department_id = d.department_id );
-- NOT IN 연산자를 사용한 결과와 동일합니다.
SELECT department_id, department_name
FROM departments d
WHERE department_id NOT IN ( SELECT department_id
FROM employees
WHERE department_id = d.department_id );

'Oracle Database' 카테고리의 다른 글
| Database_68_계층 쿼리 함수_계층 질의, Level 의사열, TOP-DOWN, BOTTOM-UP, SYS_CONNECT_BY_PATH, CONNECT_BY_ROOT (0) | 2023.08.21 |
|---|---|
| Database_67_Subquery 응용_인라인 뷰_In-Line View_Top-N 분석, WITH 절 (0) | 2023.08.20 |
| Database_65_DML 응용_FLASHBACK (0) | 2023.08.20 |
| Database_64_DML 응용_MERGE UPSERT (0) | 2023.08.20 |
| Database_63_DML 응용_PIVOTING INSERT (0) | 2023.08.20 |



