
hyeonga_code
Database_25_그룹 함수_확장 연산자_CUBE, ROLLUP, GROUPING, GROUPING SETS 본문
Database_25_그룹 함수_확장 연산자_CUBE, ROLLUP, GROUPING, GROUPING SETS
hyeonga 2023. 7. 28. 05:59

-- GROUP BY 확장 연산자
-- 상호 참조 열에 따라 상위 집계 행을 산출합니다.
-- CUBE : ROLLUP의 결과 행 및 교차 도표화 행을 포함하는 결과 집합을 산출합니다.
-- 하나의 SELECT 문으로 교차 도포화_Cross Tabulation 값을 산출할 수 있습니다.
-- ROLLUP : 정규 그룹화 행과 하위 총계 값을 포함하는 결과 집합을 산출합니다.
-- 하위 총계와 같은 누적 집계를 산출할 수 있습니다.
-- ROLLUP( 'A' , 'B' )
-- >>> A+B , A , 0
-- ROLLUP( 'A', 'B', 'C')
-- >>> A+B+C , A+B , A , 0
-- GROUPING 함수
-- GROUPING SETS
-- GROUPING_ID
-- 행에서 하위 총계를 형성한 그룹을 찾을 수 있습니다.
-- 여러 개의 매개 변수를 입력할 수 있습니다.
-- 그룹화 비트 벡터 값을 십진수로 변환하여 반환합니다.
-- GROUPING SETS
-- 같은 질의에서 여러 그룹화를 정의할 수 있습니다.
-- 그룹화 집합을 사용하면 다음과 같은 면에서 효율적입니다.
-- 기본 테이블을 한 번만 검색합니다.
-- 복잡한 UNION 문을 작성할 필요가 없습니다.
-- GROUPING SETS에 요소가 많을수록 성능이 좋아집니다.
-- GROUPING 함수는 해당 열을 사용하지 않았다는 것을 표현하기 위해 사용됩니다.
/*
-- 이 세 문장을 모두 합치고 싶은 경우
SELECT department_id, job_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
ORDER BY 1,2;
SELECT department_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
ORDER BY 1,2;
SELECT COUNT(*), SUM(salary)
FROM employees;
*/
-- 1) UNION 으로 결합
/*
SELECT department_id, job_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
UNION
SELECT department_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
UNION
SELECT COUNT(*), SUM(salary)
FROM employees
ORDER BY 1,2;
-- 컬럼 수가 맞지 않습니다.
>> 컬럼 수를 일치시킵니다.
*/
SELECT department_id, job_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
UNION
SELECT department_id, TO_CHAR(null), COUNT(*), SUM(salary)
FROM employees
GROUP BY department_id, job_id
UNION
SELECT TO_NUMBER(null), TO_CHAR(null), COUNT(*), SUM(salary)
FROM employees
ORDER BY 1,2;
/*
DP_ID JOB_ID COUNT(*) SUM(salary)
-------------------------------------------------------------------------
10 AD_ASST 1 4400
10 ( null ) 1 4400
20 MK_MAN 1 13000
20 MK_REP 1 6000
20 ( null ) 1 6000
20 ( null ) 1 13000
( null ) SA_REP 1 7000
( null ) ( null ) 1 7000
( null ) ( null ) 20 175500
*/

SELECT department_id, job_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY ROLLUP(department_id, job_id)
ORDER BY 1,2;
/*
DP_ID JOB_ID COUNT(*) SUM(salary)
-------------------------------------------------------------------------
10 AD_ASST 1 4400
10 ( null ) 1 4400
20 MK_MAN 1 13000
20 MK_REP 1 6000
20 ( null ) 1 6000
20 ( null ) 1 13000
( null ) SA_REP 1 7000
( null ) ( null ) 1 7000
( null ) ( null ) 20 175500
*/

SELECT department_id DP, job_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY CUBE(department_id, job_id)
ORDER BY 1,2;
/*
DP JOB_ID COUNT(*) SUM(salary)
------------------------------------------------------
10 AD_ASST 1 4400
10 ( null ) 1 4400
20 MK_MAN 1 13000
20 MK_REP 1 6000
20 ( null ) 2 19000
50 ST_CLERK 4 11700
50 ST_MAN 1 5800
50 ( null ) 5 17500
60 IT_PROG 3 19200
60 ( null ) 3 19200
80 SA_MAN 1 10500
80 SA_REP 2 19600
80 ( null ) 3 30100
90 AD_PRES 1 24000
90 AD_VP 2 34000
90 ( null ) 3 58000
110 AC_ACCOUNT 1 8300
110 AC_MGR 1 12000
110 ( null ) 2 20300
( null ) AC_ACCOUNT 1 8300
( null ) AC_MGR 1 12000
( null ) AD_ASST 1 4400
( null ) AD_PRES 1 24000
( null ) AD_VP 2 34000
( null ) IT_PROG 3 19200
( null ) MK_MAN 1 13000
( null ) MK_REP 1 6000
( null ) SA_MAN 1 10500
( null ) SA_REP 1 7000
( null ) SA_REP 3 26600
( null ) ST_CLERK 4 11700
( null ) ST_MAN 1 5800
( null ) ( null ) 1 7000
( null ) ( null ) 20 175500
*/
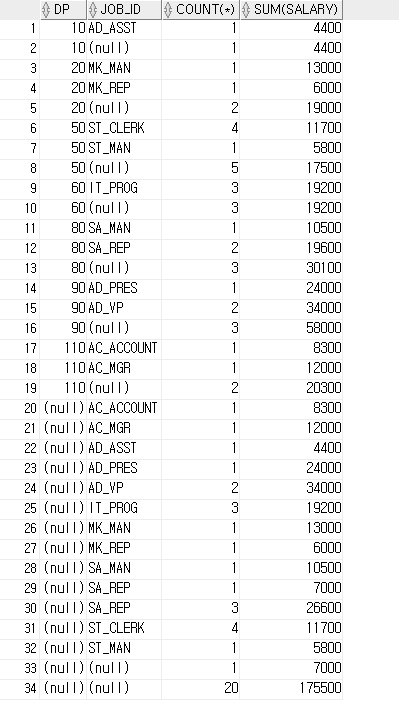
SELECT department_id DP, job_id, manager_id, COUNT(*), SUM(salary)
FROM employees
GROUP BY CUBE(department_id, job_id, manager_id)
ORDER BY 1,2;
-- 반환값 0/1
SELECT department_id DP, job_id, manager_id MG, COUNT(*), SUM(salary)
FROM employees
GROUP BY GROUPING SETS((department_id, job_id), (manager_id), ())
ORDER BY 1,2;

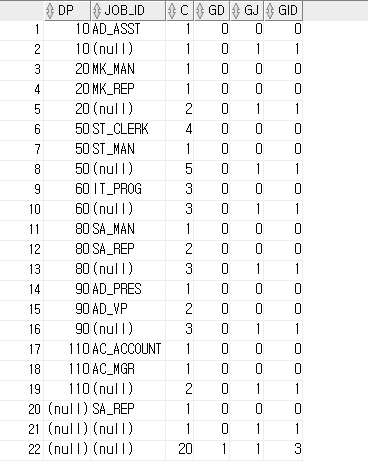
SELECT department_id DP, GROUPING(department_id) GR_D,
job_id, GROUPING(job_id) GR_J,
manager_id MG, GROUPING(manager_id) GR_M,
COUNT(*), SUM(salary)
FROM employees
GROUP BY GROUPING SETS((department_id, job_id), (manager_id), ())
ORDER BY 1,2;

-- GROUPING_ID
SELECT department_id DP, GROUPING(department_id) GR_D,
job_id, GROUPING(job_id) GR_J,
COUNT(*), SUM(salary),
GROUPING_ID(department_id, job_id) GID
FROM employees
GROUP BY GROUPING SETS((department_id, job_id), ())
ORDER BY 1,2;
/*
DP GR_D JOB_ID GR_J C S GID
-------------------------------------------------------------------
10 0 AD_ASST 0 1 4400 0
20 0 MK_MAN 0 1 13000 0
20 0 MK_REP 0 1 6000 0
50 0 ST_CLERK 0 4 11700 0
50 0 ST_MAN 0 1 5800 0
60 0 IT_PROG 0 3 19200 0
80 0 SA_MAN 0 1 10500 0
80 0 SA_REP 0 2 19600 0
90 0 AD_VP 0 2 34000 0
90 0 AD_PRES 0 1 24000 0
110 0 AC_MGR 0 1 12000 0
110 0 AC_ACCOUNT 0 1 8300 0
(null) 0 SA_REP 0 1 7000 0
(null) 1 ( null ) 1 20 175500 3 -- 이진수 11 > 십진수 3
*/

SELECT department_id DP, GROUPING(department_id) GR_D,
job_id, GROUPING(job_id) GR_J,
COUNT(*), SUM(salary),
GROUPING_ID(department_id, job_id) GID
FROM employees
GROUP BY ROLLUP(department_id, job_id)
ORDER BY 1,3;
-- 1:1 >> 3

SELECT department_id DP, GROUPING(department_id) GR_D,
job_id, GROUPING(job_id) GR_J,
COUNT(*), SUM(salary),
GROUPING_ID(department_id, job_id) GID
FROM employees
GROUP BY CUBE(department_id, job_id)
ORDER BY 1,3;
-- jpb_id를 사용한 것은 1, 0 >> 2

SELECT department_id dp, job_id job_id, COUNT(*) c,
GROUPING(department_id) gd, GROUPING(job_id) gj,
GROUPING_ID(department_id, job_id) gid
FROM employees
GROUP BY ROLLUP(department_id, job_id)
ORDER BY 1,2;
-- LISTAGG 함수
-- 여러 행의 열 값을 한 행의 값으로 가져와야 하는 경우 사용합니다.
-- 그룹화된 개별 데이터를 하나의 열에 가로로 출력합니다.
/*
SELECT LISTAGG( column1, 구분자 ) WITHIN GROUP (ORDER BY column2)
FROM table
*/
-- LISTAGG 함수의 인수인 column_name은 가로로 나열할 열의 이름입니다.
-- ORDER BY 절을 사용하여 가로로 출력될 데이터를 정렬합니다.
SELECT department_id, COUNT(*),
LISTAGG(last_name, ',') WITHIN GROUP(ORDER BY salary DESC) AS ename
FROM employees
GROUP BY department_id;
/*
DP_ID COUNT(*) ENAME
-------------------------------------------------------------------------------------------
10 1 Whalen
20 2 Hartstein,Fay
50 5 Mourgos,Rajs,Davies,Matos,Vargas
60 3 Hunold,Ernst,Lorentz
80 3 Abel,Zlotkey,Taylor
90 3 King,De Haan,Kochhar
110 2 Higgins,Gietz
(null) 1 Grant
*/

-- PIVOT 함수
-- 기존 테이블의 행을 열로 변경하여 출력합니다.
/*
SELECT column1
FROM [table | Subquery]
PIVOT(
group_function FOR column2 IN (value,...)
)
[ORDER BY ...];
*/
SELECT *
FROM (SELECT department_id, job_id, salary FROM employees
WHERE department_id IN (50,60, 80))
PIVOT(MAX(salary) FOR department_id IN (50, 60, 80));
/*
JOB_ID 50 60 80
---------------------------------------------
IT_PROG (null) 9000 (null)
ST_MAN 5800 (null) (null)
SA_MAN (null) (null) 10500
SA_REP (null) (null) 11000
ST_CLERK 3500 (null) (null)
*/

SELECT *
FROM (
SELECT job_id ,
TO_CHAR(hire_date, 'fmMM') || '월' AS hire_month
FROM employees
)
PIVOT (
COUNT(*)
FOR hire_month IN ('1월','2월','3월','4월','5월','6월',
'7월','8월','9월','10월','11월','12월')
);
/* == 동일 코드입니다.
SELECT job_id
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '1', 1, 0)) "1월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '2', 1, 0)) "2월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '3', 1, 0)) "3월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '4', 1, 0)) "4월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '5', 1, 0)) "5월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '6', 1, 0)) "6월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '7', 1, 0)) "7월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '8', 1, 0)) "8월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '9', 1, 0)) "9월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '10', 1, 0)) "10월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '11', 1, 0)) "11월"
, SUM(DECODE(TO_CHAR(hire_date, 'fmMM'), '12', 1, 0)) "12월"
FROM employees
GROUP BY job_id;
*/

'Oracle Database' 카테고리의 다른 글
| Database_27_ANSI JOIN_조인 함수 Natural JOIN (0) | 2023.07.30 |
|---|---|
| Database_26_ANSI JOIN_조인이 필요한 이유 (0) | 2023.07.29 |
| Database_24_그룹 함수_AVG, SUM, MAX, MIN, COUNT (0) | 2023.07.27 |
| Database_23_일반 함수_조건 표현식_CASE, DECODE (0) | 2023.07.26 |
| Database_22_일반 함수_함수의 중첩 (0) | 2023.07.25 |



