
hyeonga_code
Database_71_정규화 표현식, 정규식 함수_REGEXP_LIKE, REGEXP_REPLACE, REGEXP_INSTR, REGEXP_SUBSTR, REGEXP_COUNT, META CHARACTER 본문
Database_71_정규화 표현식, 정규식 함수_REGEXP_LIKE, REGEXP_REPLACE, REGEXP_INSTR, REGEXP_SUBSTR, REGEXP_COUNT, META CHARACTER
hyeonga 2023. 8. 23. 05:59
-- 정규화 표현식
-------------------------------------------------------------------------------------------------------------
SELECT employee_id, last_name
FROM employees
WHERE ( last_name LIKE 'K%'
OR last_name LIKE 'H%' )
AND last_name LIKE '%i%';

SELECT employee_id, last_name, SUBSTR(last_name, 2, 4), INSTR(last_name, 'a')
FROM employees;

SELECT employee_id, last_name
FROM employees
WHERE SUBSTR(last_name, -1, 1)='s';

SELECT employee_id, last_name
FROM employees
WHERE INSTR(last_name, 't') <> 0;

SELECT employee_id, phone_number, REPLACE(phone_number, '.', '-') AS new_phone_no
FROM employees;

-------------------------------------------------------------------------------------------------------------
-- 정규식
-- 표준 구문 규칙을 사용하여 문자열 데이터의 간단한 패턴 및 복잡한 패턴을 검색하고 조작할 수 있습니다.
-- SQL 함수 및 조건 집합을 사용하여 SQL 및 PL/SQL에서 문자열을 검색하고 조작할 수 있습니다.
-- 지정 방식
-- 메타 문자 : 검색 알고리즘을 지정하는 연산자
-- 리터럴 : 검색 중인 문자
-- 이점
-- 데이터베이스에서 복잡한 일치 논리를 구현하는 경우
-- 일치 논리를 중앙화 합니다.
-- MIDDLE-TIER 응용 프로그램에 의한 SQL 결과 집합의 집중적인 문자열 처리를 방지할 수 있습니다.
-- 서버측 정규식을 사용하여 제약 조건을 적용합니다.
-- 클라이언트에서 데이터 검증 논리 코드를 작성할 필요가 없습니다.
-- 함수와 함께 작성하여 문자열을 조작할 수 있습니다.
-- 정규식 함수
-- REGEXP_LIKE
-- 정규식 일치를 수행합니다.
/*
SELECT column
FROM table
WHERE REGEXP_LIKE( column 1, 'find text' );
*/
-- REGEXP_REPLACE
-- 정규식 패턴을 검색하여 대체 문자열로 수정합니다.
-- REGEXP_INSTR
/*
SELECT column, REGEXP_INSTR( '컬럼 이름', '대체 문장' )
FROM table;
*/
-- 정규식 패턴에 대해 문자열을 검색하고 일치가 발견된 위치를 반환합니다.
-- REGEXP_SUBSTR
-- 지정된 문자열 내에서 정규식 패턴을 검색하고 일치하는 부분 문자열을 추출합니다.
-- REGEXP_COUNT
-- 입력 문자열에서 패턴 일치가 발견되는 횟수를 반환합니다.
-- 일치하는 데이터가 없는 경우 0을 반환합니다.
-- META CHARACTER
-- 대체 문자, 반복 문자, 일치하지 않는 문자 또는 일련의 문자
-- 패턴 일치에서 여러 가지 미리 정의된 메타 문자 기호를 사용할 수 있습니다.
-- 종류
/*
. : 지원되는 Character Set에서 NULL을 제외한 임의의 문자와 일치하는지
+ : 한 번 이상 발생하는 수가 일치하는지
? : 0 또는 1번 발생 수 일치
* : 선행 하위식의 0번 이상 발생 수 일치
{m} : 선행 표현식에서 m번 발생 수 일치
{ m , } : 선행 하위식과 최소 m번 이상
{ m, n } : 선행 하위식과 최소 m번부터 최대 n번 이하
[ ... ] : 괄호 안의 리스트에 있는 임의의 단일 문자와 일치하는지
| : 여러 대안 중 하나와 일치하는지
( ... ) : 괄호로 묶인 표현식을 한 단위로 취급합니다.
^ : 바로 뒤에 나오는 문자가 문자열 시작 부분과 일치하는지
$ : 달러 앞의 문자가 문자열 끝 부분과 일치하는지
\ : 표현식에서 후속 메타 문자를 리터럴로 처리합니다. ESCAPE
\n : 괄호 안의 그룹화된 n번째 (1-9) 선행 하위식과 일치하는지
-- 괄호는 표현식이 기억되도록 합니다.
-- backreference
\d : 숫자 문자
[ :class: ] : 지정된 POSIX 문자 클래스에 속한 임의의 문자와 일치하는지
-- alpha : 알파벳
-- digit : 숫자
-- lower : 소문자
-- upper : 대문자
-- alnum : 알파벳 + 숫자
-- space : 공백 문자
-- punct : 구두점 기호
-- cntrl : 컨트롤 문자
-- print : 출력이 가능한 문자
[^:class:] : 괄호 안의 리스트에 없는 임의의 단일 문자와 일치하는지
*/
----------------------------------------------------------
-- ^(f|ht)tps?:$
-- ^ : 시작을 알립니다.
-- (f | ht) : 목록을 의미합니다.
-- s? : 들어가거나 들어가지 않습니다.
-- :$ : :으로 끝나야 합니다.
----------------------------------------------------------
---------------------------
----- 실습 준비
-- 테이블 생성
CREATE TABLE t1
( empno NUMBER(6),
fname VARCHAR2(10),
lname VARCHAR2(10),
phone VARCHAR2(20),
addr VARCHAR2(40)) ;
/*
Table T1이(가) 생성되었습니다.
*/
-- 데이터 삽입
INSERT INTO T1 VALUES (200,'Jennifer','Whalen','515.123.4444','2004 Charade Rd');
INSERT INTO T1 VALUES (201,'Michael','Hartstein','515.123.5555','147 Spadina Ave');
INSERT INTO T1 VALUES (114,'Den','Raphaely','515.127.4561','2004 Charade Rd');
INSERT INTO T1 VALUES (203,'Susan','Mavris','515.123.7777','8204 Arthur St');
INSERT INTO T1 VALUES (137,'Renske','Ladwig','650.121.1234','2011 Interiors Blvd');
INSERT INTO T1 VALUES (106,'Valli','Pataballa','590.423.4560','2014 Jabberwocky Rd');
INSERT INTO T1 VALUES (204,'Stephen','Baer','010.45.1343.329ABC','Schwanthalerstr. 7031');
INSERT INTO T1 VALUES (173,'Sundita','Kumar','011.44.1343.329268','Magdalen Centre, The Oxford Science Park');
INSERT INTO T1 VALUES (100,'Steven','King','515.123.4567','2004 Charade Rd');
INSERT INTO T1 VALUES (109,'Daniel','Faviet','515.124.4169','2004 Charade Rd');
INSERT INTO T1 VALUES (205,'Shelley','Higgins','515.123.8080','2004 Charade Rd');
/*
11 행 이(가) 삽입되었습니다.
*/
-- 커밋
COMMIT ;
/*
커밋 완료.
*/
-- 데이터 조회
SELECT * FROM t1;

-----실습 준비 완
-----------------------------------
-- ESCAPE : 대체 문자가 아님을 명시해야 합니다.
-- REGEXP_LIKE
-- 첫 인수 컬럼에서 '찾을 내용'을 검색합니다.
SELECT fname, lname
FROM t1
WHERE REGEXP_LIKE ( fname, '^Ste(v|ph)en$' );

--
SELECT fname, phone
FROM t1
WHERE REGEXP_LIKE ( phone, '...\...\.....\.......' );
-- (period) : 임의의 한 문자
-- \. : \ 뒤에 나오는 데이터는 리터럴 문자입니다.(ESCAPE)
-- @@@ . @@ . @@@@ . @@@@@@

SELECT fname, phone
FROM t1
WHERE REGEXP_LIKE ( phone, '[0-9]{3}\.[0-9]{2}\.[0-9]{4}\.[0-90]{6}');

SELECT fname, phone
FROM t1
WHERE REGEXP_LIKE ( phone, '\d{3}\.\d{2}\.\d{4}\.\d{6}');
-- [0-9] : 0 부터 9까지의 숫자 (범위 지정)
-- \d : 숫자 문자
-- {m} : m번 반복

-- REGEXP_REPLACE
SELECT empno, phone, REGEXP_REPLACE ( phone, '(\d{3})\.(\d{3})\.(\D{4})', '(\1)-\2-\3') AS new_phone
FROM t1;
-- (\d{3})\.(\d{3})\.(\D{4}) : 3 자리로 표시되는 전화번호 검색
-- (\1)-\2-\3 : 3개의 그룹 문자를 표현하여 1번 그룹을 ( )로 감사고 구분자를 '-'로 지정합니다.

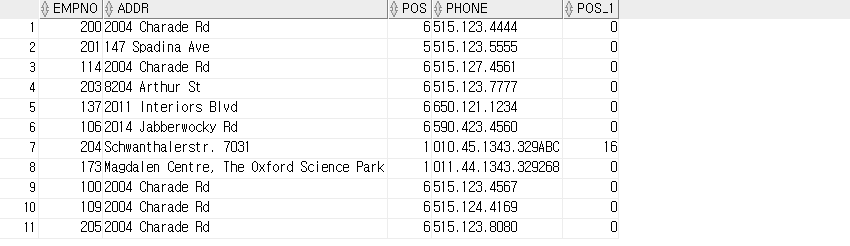
-- REGEXP_INSTR
SELECT empno, addr, REGEXP_INSTR ( addr, '[[:alpha:]]' ) pos , phone, REGEXP_INSTR ( phone, '[[:alpha:]]') pos
FROM t1 ;
-- [ : 표현식 시작
-- [[:alpha:]] : 알파벳 문자
-- ] : 표현식 종료
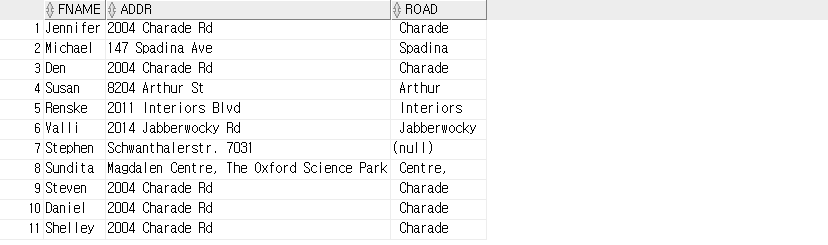
-- REGEXP_SUBSTR
SELECT fname, addr, REGEXP_SUBSTR ( addr, ' [^ ]+ ') road
FROM t1 ;
-- ^ : 부정형 의미 ( 빈 공백이 아닌 문자 )
-- + : 1 개 이상
-- □[^□]+□ : 빈 공백 문자 뒤에 공백이 아닌 문자가 하나 이상 존재하고 공백이 마지막에 붙어있는 부분 문자 추출 ( □ => 공백 문자 )
SELECT fname, phone, REPLACE(REGEXP_SUBSTR(phone,'\.(\d{3})\.'),'.') code
FROM t1 ;

-- REGEXP_COUNT
-- 'a'가 발견된 횟수를 검색합니다.
SELECT REGEXP_COUNT(addr,'a') cnt , fname, addr
FROM t1 ;

-- 일반 함수와 중첩 사용
-- 정규식 함수를 중첩 등의 방식으로 일반 함수와 함께 사용할 수 있습니다.
-- \. : 국번 앞,뒤로 나오는 "." ( \ => ESCAPE )
-- (\d{n}) : 숫자 n자리
-- 지역 번호를 뺀 국번만 조회합니다.
SELECT fname, phone,
REPLACE (REGEXP_SUBSTR(phone, '\.(\d{3})\.'), '.') code
FROM t1;

-- Subexpressions_하위식
-- REGEXP_INSTR, REGEXP_SUBSTR에서 지원합니다.
-- 특정 패턴, 표현식을 하나의 항목으로 처리하는 것입니다.
-- 문자열 내의 하위식을 식별하기 위해 소괄호를 사용합니다.
-- 밖에서 안으로 들어가는 순서입니다.
-- 왼쪽에서부터 순서입니다.
-- c : 대소문자 구분
-- i : 대소문자 구분 안함
SELECT REGEXP_SUBSTR ('0123456789', '(123)(4(56)(78))', 1, 1, 'i', 1 ) "Exp1" ,
REGEXP_SUBSTR ('0123456789', '(123)(4(56)(78))', 1, 1, 'i', 2 ) "Exp2" ,
REGEXP_SUBSTR ('0123456789', '(123)(4(56)(78))', 1, 1, 'i', 3 ) "Exp3" ,
REGEXP_SUBSTR ('0123456789', '(123)(4(56)(78))', 1, 1, 'i', 4 ) "Exp4"
FROM dual;
-- 첫 번째 하위식은 첫 괄호인 123입니다.
-- 두 번째 하위식은 남은 괄호 중 가장 밖의 괄호인 45678입니다.
-- 세 번째 하위식은 안의 괄호 중 왼쪽에 위치한 56입니다.

SELECT REGEXP_INSTR ('0123456789','(123)(4(56)(78))', 1, 1, 0, 'i', 2 )
AS "Position"
FROM dual ;

-- DNA에서 특정 하위 패턴을 조회합니다.
SELECT
REGEXP_INSTR('ccacctttccctccactcctcacgttctcacctgtaaagcgtccctc
cctcatccccatgcccccttaccctgcagggtagagtaggctagaaaccagagagctccaagc
tccatctgtggagaggtgccatccttgggctgcagagagaggagaatttgccccaaagctgcc
tgcagagcttcaccacccttagtctcacaaagccttgagttcatagcatttcttgagttttca
ccctgcccagcaggacactgcagcacccaaagggcttcccaggagtagggttgccctcaagag
gctcttgggtctgatggccacatcctggaattgttttcaagttgatggtcacagccctgaggc
atgtaggggcgtggggatgcgctctgctctgctctcctctcctgaacccctgaaccctctggc
taccccagagcacttagagccag',
'(gtc(tcac)(aaag))',
1, 1, 0, 'i',
1) "Position"
FROM dual;

'Oracle Database' 카테고리의 다른 글
| Database_72_DATETIME 응용_TIMESTAMP (0) | 2023.08.24 |
|---|---|
| Database_72_DATETIME 응용_데이터베이스 기반, 사용자 세션 날짜 (0) | 2023.08.24 |
| Database_69_그룹 함수_LISTAGG 함수, PIVOT 함수 (0) | 2023.08.22 |
| Database_70_윈도우 함수_그룹 내 순위, 그룹 내 집계, 그룹 내 행 순서, 그룹 내 비율 (0) | 2023.08.22 |
| Database_68_계층 쿼리 함수_계층 질의, Level 의사열, TOP-DOWN, BOTTOM-UP, SYS_CONNECT_BY_PATH, CONNECT_BY_ROOT (0) | 2023.08.21 |



