hyeonga_code
Database_70_윈도우 함수_그룹 내 순위, 그룹 내 집계, 그룹 내 행 순서, 그룹 내 비율 본문

-- 윈도우 함수
-- 관계형 데이터베이스의 행과 행간의 관계를 쉽게 정의하기 위해 만든 함수입니다.
-- 복잡한 프로그램을 하나의 SQL 문장으로 쉽게 해결할 수 있습니다.
-- 데이터웨어하우스에서 발전한 기능입니다.
-- =분석 함수_ANALYTIC FUNCTION
-- =순위 함수_RANK FUNCTION
-- 기존에 사용하던 그룹 함수에 WINDOW 함수 전용으로 만들어진 기능이 포함되어 있습니다.
-- 중첩하여 사용할 수 없습니다.
-- 서브쿼리에 사용할 수 있습니다.
-- 종류
-- 그룹 내 순위_RANK
-- RANK
-- ORDER BY를 포함한 QUERY 문에서 특정 항목에 대한 순위를 구하는 함수입니다.
-- 특정 범위 내에서 또는 전체 데이터에 대한 순위를 구할 수도 있습니다.
-- 동일한 값에 대해서는 동일한 순위를 부여하게 됩니다.
-- DENSE_RANK
-- RANK 함수와 유사합니다.
-- 동일한 순위를 하나의 건수로 취급하는 것이 다릅니다.
-- ROW_NUMBER
-- 동일한 값이라도 고유한 순위를 부여합니다.
-- 그룹 내 집계_AGGREGATE
-- SUM
-- 파티션 별 윈도우의 합을 구할 수 있습니다.
-- SUM 누적값 출력
-- OVER 절 내에 ORDER BY절을 작성하여 파티션 내의 데이터를 정렬한 후 이전 salary 데이터까지의 누적을 출력할 수 있습니다.
-- MAX
-- 파티션 별 윈도우의 최대값을 구할 수 있습니다.
-- MIN
-- 파티션 별 윈도우의 최소값을 구할 수 있습니다.
-- AVG
-- 파티션 별 윈도우의 평균값을 구합니다.
-- ROWS BETWEEN 절을 사용하여 현재 행을 기준으로 파티션 내에서 범위로 지정할 수 있습니다.
-- COUNT
-- 파티션 별 ROWS 윈도우를 이용하여 원하는 조건에 맞는 데이터에 대한 통계값을 구할 수 있습니다.
-- 그룹 내 행 순서 : Oracle 지원
-- FIRST_VALUE
-- 파티션 별 윈도우에서 가장 먼저 나온 값을 구할 수 있습니다.
-- LAST_VALUE
-- 파티션 별 윈도우에서 가장 나중에 나온 값을 구할 수 있습니다.
-- LAG
-- 파티션 별 윈도우에서 이전 몇 번 째 행의 값을 가져올 수 있습니다.
-- LEAD
-- 파티션 별 윈도우에서 이후 몇 번째 행의 값을 가져올 수 있습니다.
-- 그룹 내 비율
-- ANSI/ISO SQL 표준
-- CUME_DIST
-- 파티션 별 윈도우의 전체 건 수에서 현재 행보다 작거나 같은 건에 대한 누적 백분율을 구할 수 있습니다.
-- 결과 값은 >0 & <=1의 범위를 가집니다.
-- PERCENT_RANK
-- 파티션 별 윈도우에서 제일 먼저 나오는 것을 0, 제일 늦게 나오는 것을 0으로 합니다.
-- 값이 아닌 행의 순서별 백분율을 구할 수 있습니다.
-- 결과 값은 >=0 & <=1의 범위를 가집니다.
-- Oracle 지원
-- NTILE
-- RATIO_TO_REPORT
-- 파티션 내 전체 SUM 값에 대한 행 별 열 값의 백분율을 소수점으로 구할 수 있습니다.
-- 결과 값은 >0 & <= 1의 범위를 가지며 개별 RATIO의 합을 구하면 1이 됩니다.
-- 구문
/*
SELECT WINDOW_FUNCTION ( ARGUEMENTS ) OVER ( [ PARTITION BY column ]
[ ORDER BY ]
[ WINDOWING ] )
FROM table;
-- ARGUEMENTS : 함수에 따라 0-N개의 인수를 지정합니다.
-- PARTITION BY column : 전체 집합을 기준에 의해 소그룹으로 나눕니다.
-- ORDER BY : 어떤 항목에 대해 순위를 지정할 지 작성합니다.
-- WINDOWING : 함수의 대상이 되는 행 기준의 범위를 ROWS/RANGE로 지정합니다.
-- ROWS : 물리적인 결과 행의 수
-- RANGE : 논리적인 값에 의한 범위
*/
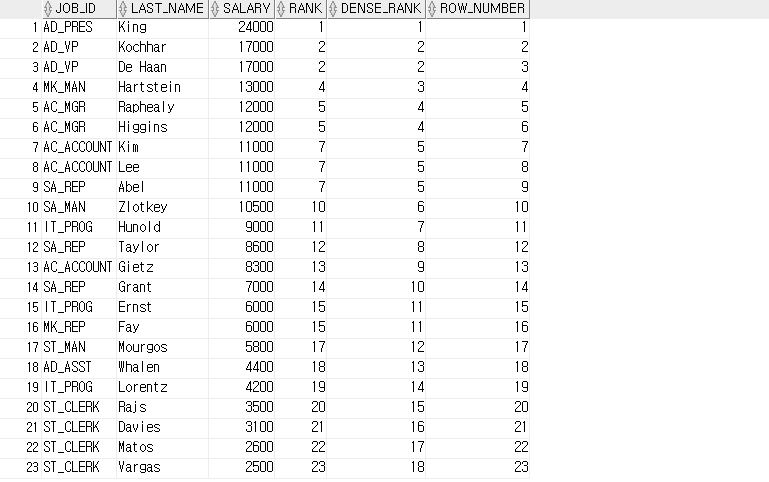
-- 그룹 내 순위 : RANK, DENSE_RANK, ROW_NUMBER
SELECT job_id, last_name, salary, RANK( ) OVER ( ORDER BY salary DESC ) RANK,
DENSE_RANK( ) OVER ( ORDER BY salary DESC ) DENSE_RANK,
ROW_NUMBER ( ) OVER ( ORDER BY salary DESC ) ROW_NUMBER
FROM employees;
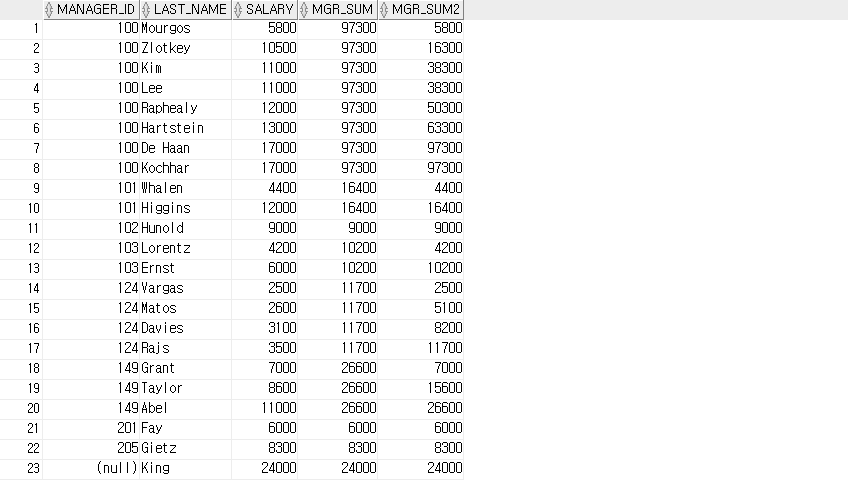
-- 그룹 내 집계_AGGREGATE
-- SUM
SELECT manager_id, last_name, salary, SUM(salary) OVER ( PARTITION BY manager_id ) AS mgr_SUM,
SUM(salary) OVER ( PARTITION BY manager_id ORDER BY salary RANGE UNBOUNDED PRECEDING) AS mgr_SUM2
FROM employees;
-- ORDER BY hire_date 를 작성하면 이전 행의 누적으로 출력됩니다.
-- ORDER BY hire_date RANGE UNBOUNDED PRECEDING 를 작성해도 DEFAULT 값으로 출력됩니다.
-- PARTITION BY manager_id ORDER BY hire_date를 작성하면 입사일을 기준으로 파티션마다 정렬되며 누적분이 초기화됩니다.
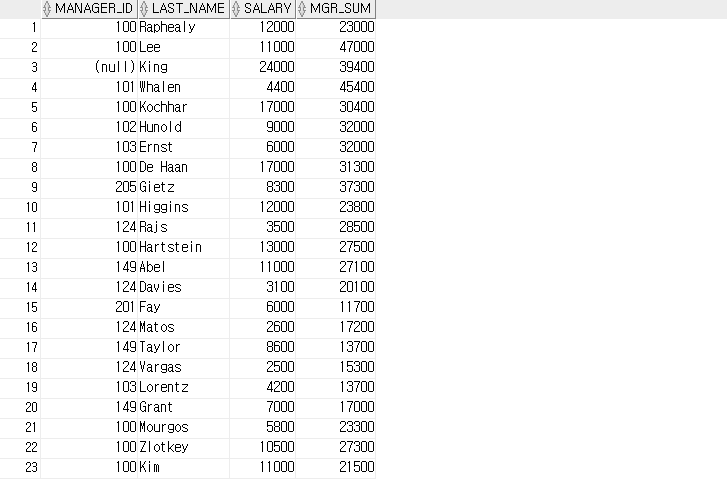
-- 현재 행을 기준으로 위 아래까지의 합을 실행합니다.
SELECT manager_id, last_name, salary,
SUM(salary) OVER ( ORDER BY hire_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) AS mgr_SUM
FROM employees;
-- MAX/MIN
SELECT manager_id, last_name, salary,
MAX(salary) OVER ( PARTITION BY manager_id ) AS manager_max,
MIN(salary) OVER ( PARTITION BY manager_id ) AS manager_min
FROM employees;

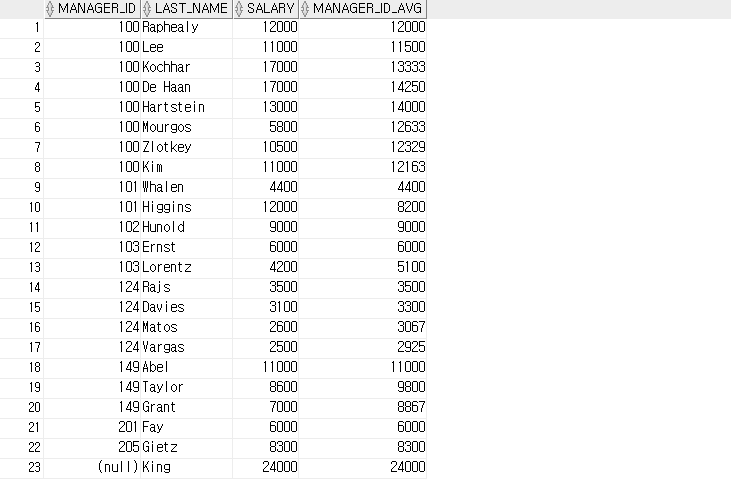
-- AVG
SELECT manager_id, last_name, salary,
ROUND( AVG(salary) OVER (PARTITION BY manager_id ORDER BY hire_date)) AS manager_id_avg
FROM employees;
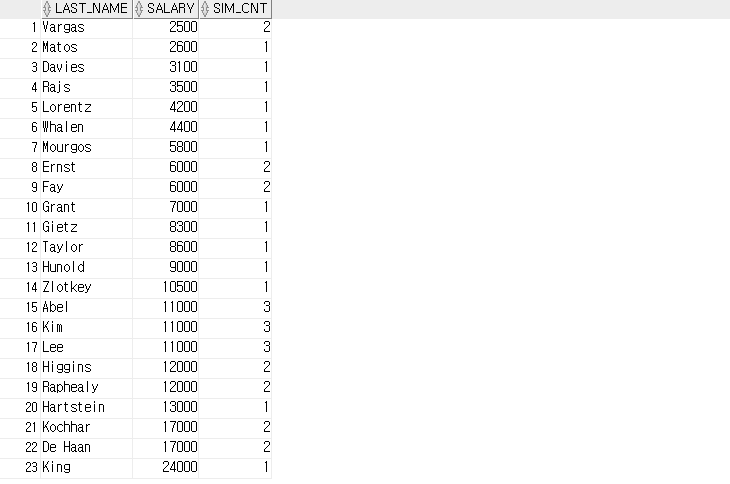
-- COUNT
SELECT last_name, salary, COUNT(*) OVER( ORDER BY salary RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING ) AS sim_cnt
FROM employees;
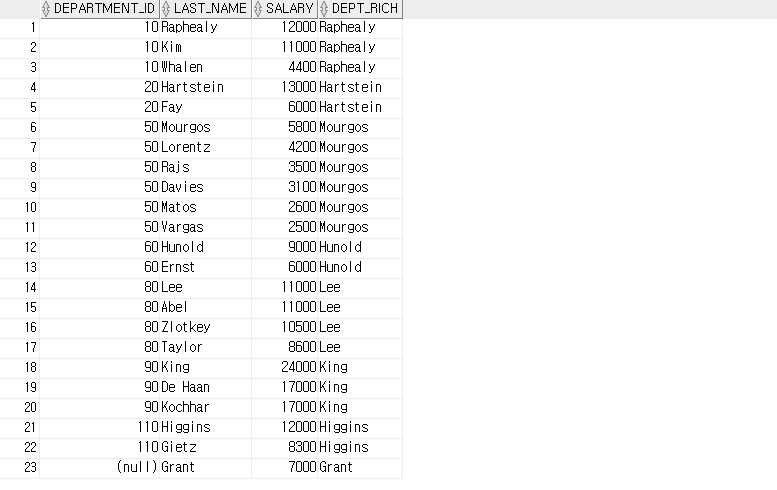
-- 그룹 내 행 순서 : FIRST_VALUE, LAST_VALUE, LAG, LEAD
-- FIRST_VALUE
SELECT department_id, last_name, salary,
FIRST_VALUE(last_name) OVER ( PARTITION BY department_id ORDER BY salary DESC ROWS UNBOUNDED PRECEDING ) AS dept_rich
FROM employees;
SELECT department_id, last_name, salary,
FIRST_VALUE(last_name) OVER ( PARTITION BY department_id
ORDER BY salary DESC, last_name
ROWS UNBOUNDED PRECEDING ) AS dept_rich
FROM employees;

-- LAST_VALUE
SELECT department_id, last_name, salary,
LAST_VALUE(last_name) OVER ( PARTITION BY department_id
ORDER BY salary DESC
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS dept_poor,
LAST_VALUE(last_name) OVER ( PARTITION BY department_id ORDER BY salary DESC ) AS dept_poor2
FROM employees;

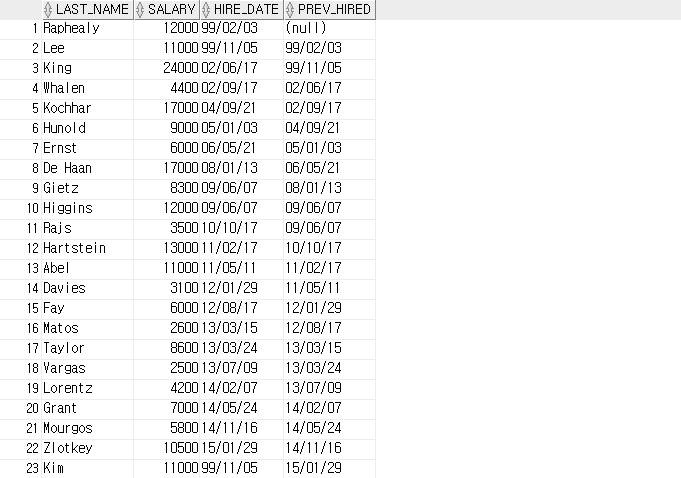
-- LAG
SELECT last_name, salary, hire_date, LAG(hire_date, 1) OVER ( ORDER BY hire_date ) AS prev_hired
FROM employees;
-- DEFAULT 값을 지정된 컬럼과 동일한 타입의 데이터형식으로 작성해야 합니다.
SELECT last_name, hire_date, LAG(hire_date, 1, sysdate) OVER ( ORDER BY hire_date ) AS prev_hired
FROM employees;

-- LEAD
SELECT last_name, hire_date, LEAD(hire_date) OVER (ORDER BY hire_date) as "NEXTHIRED"
FROM employees;

-- 그룹 내 비율 : CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT
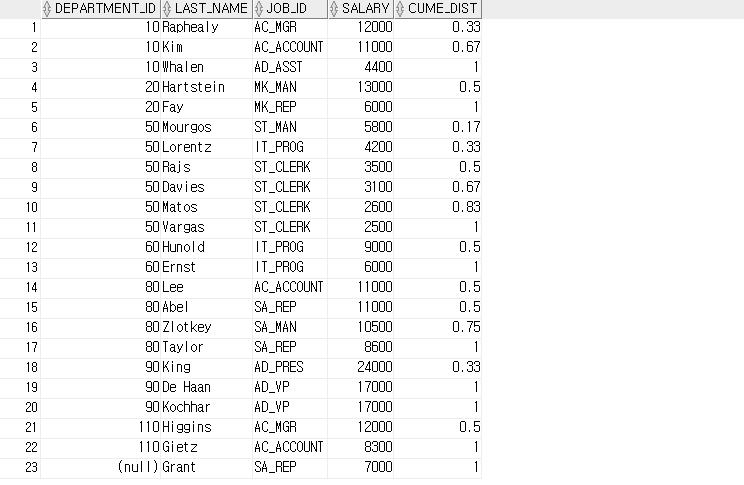
-- CUME_DIST
-- 같은 부서 직원의 집합에서 급여가 누적 순서 상 몇 번째 위치에 있는지 출력합니다.
SELECT department_id, last_name, job_id, salary,
ROUND( CUME_DIST( ) OVER ( PARTITION BY department_id ORDER BY salary DESC ), 2) AS CUME_DIST
FROM employees;
-- PERCENT_RANK
-- 같은 부서 직원의 집합에서 급여가 순서상 몇 번째 위치에 있는지 출력합니다.
SELECT department_id, last_name, job_id, salary,
PERCENT_RANK( ) OVER (PARTITION BY department_id ORDER BY salary DESC) AS P_R,
TRUNC( PERCENT_RANK( ) OVER ( PARTITION BY department_id ORDER BY salary DESC), 2) AS P_R2
FROM employees;

-- NTILE
-- 급여가 높은 순서로 정렬한 뒤, 급여를 기준으로 4개의 그룹으로 분류합니다.
-- 남은 행은 앞의 조부터 수가 추가 됩니다.
SELECT NTILE(4) OVER ( ORDER BY salary DESC ) AS QUAR_TILE, salary, last_name
FROM employees;

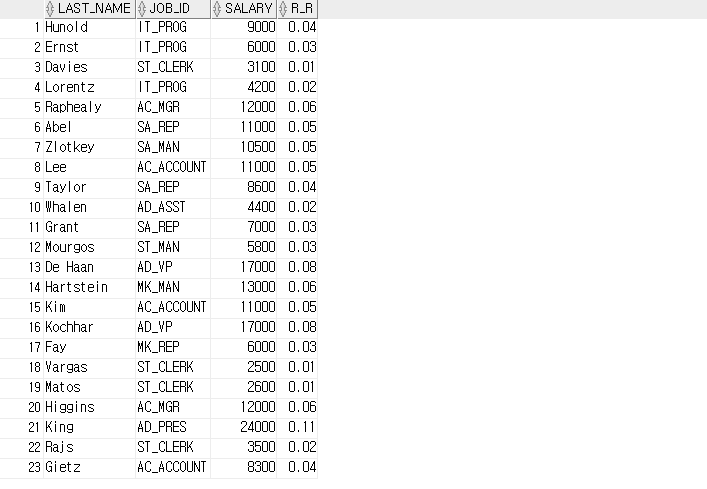
-- RATIO_TO_REPORT
-- 부서에 다니는 사람들의 총 합 급여 중 비중이 얼마나 되는지 조회합니다.
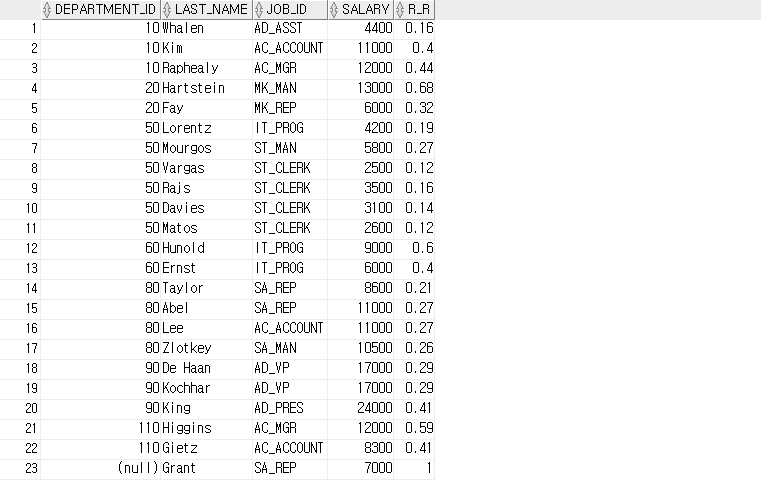
SELECT last_name, job_id, salary, ROUND( RATIO_TO_REPORT(salary) OVER ( ), 2) AS R_R
FROM employees
WHERE job_id='IT_PROG';

SELECT last_name, job_id, salary, ROUND( RATIO_TO_REPORT(salary) OVER ( ), 2) AS R_R
FROM employees;
SELECT department_id, last_name, job_id, salary, ROUND( RATIO_TO_REPORT(salary) OVER (PARTITION BY department_id), 2) AS R_R
FROM employees;